“Any sufficiently advanced technology is indistinguishable from magic.”
Arthur C. Clarke
—
Unfortunately, our friend ChatGPT and his compadre of stochastic parrots are not magic, but instead are complex webs of weightings that are developed after processing huge amounts of data. Each word and phrase fed into the system exists in some form of a relationship to the other words.
I imagine that words and phrases put into the model are like a bounding pachinko ball, pulled by the “gravity” of different terms to find where they eventually land in the space. If I drop in a ball, it will be go through various layers (dimensions) of the language model, being pulled and repulsed by different terms, dependent upon how the model categorizes it.
Let’s imagine a very simple trajectory. We drop a ball in our transdimensional pachinko machine labeled “brother”.
First, it goes through a parts of speech layer, and is pulled strong by the term “noun”.
Then, it goes through the gender layer, and is pulled more closely to the “male” group.
Finally, it lands somewhere in the “family” unit, with all the relationships that entails.
ChatGPT works like this, except instead of the couple of parameters that influenced our pachinko ball (noun, male and family), it has 175 billion.
Embedded Assumptions
In this blog I outline my growing understandings (in all their deficits), of how these models work – offering embellished and indulgent metaphors to do so. Then, we will dive in and take a look at the inner-clockworks of the machine, hallucinating our own assumptions on how these doohickeys come to make their words align. Let me be clear, this isn’t all speculation, and there are other, far more effective ways to go about analyzing vector and embedding space, but outlining my route to understanding will hopefully guide others as well.
Soon after committing to replacing teachers with robots and automating the boring stuff so teachers can focus on, you know, teaching and their students, I found myself wanting more. Generative text is an incredible new frontier, but its not magic, I sought to uncover the clockwork behind it that makes it tick.
I caught a glimpse behind the mirror with OpenAI’s embeddings endpoint. Natural Language Models are developed by feeding a huge volume of data into a neural network. This eventually creates a complex “embedding space” where words reside. There is some complexity to how this all comes together, but the best way to think about it is this….
By knowing where objects sit in the “embedding space” we can see which words are more closely related to each other. This can help us to identify bias which are endemic to the nature of the models, after all, the texts they have read are written by humans who have a track-record of being less than purely objective and rational.
The System
I’ve designed a simple system that can take a list of words, call OpenAI to get their embeddings, and then store them in a Pinecone vector database. This is a special database that can save where words reside, and then tell you their “proximity” to new words and phrases that you send. I’ve curated a few sets of words (gender, parts of speech) that we will use in this post to explore some of the connections and relationships that GPT-3 makes between words.
I’ve built in an additional feature that allows me to make groupings of words as well. So for gender groupings, I can feed in gender terms (male, masculine, man, boy, son, father/female, feminine, woman, girl, daughter, mother) and find the relationship a word has to a specific word, as well as the relationship it has to the cluster or group of words.
If you want to try it yourself, shoot me an email. I’m not convinced anyone cares enough for me to make it anything but Ryan-able, but if there is interest, I’m happy to get it into a shape where you can play with it without any technical knowledge or background setting up Node.JS servers.
Following the Bouncing Ball
So let’s track our pachinko ball through its relationships.
In our pinecone database, I’ve created two “namespaces” of words. This means, I can send a term and find its relationship to other words in the namespace. It makes it a bit easier to organize. Our first name space is parts of speech. It’s comprised of the following words:
parts_of_speech = [ "noun", "pronoun", "verb", "adjective", "adverb", "preposition", "conjunction", "interjection", "subject", "object",];So let’s send in the word “brother”, and find which part of speech (noun, verb, object, etc.) it lands most closely to:
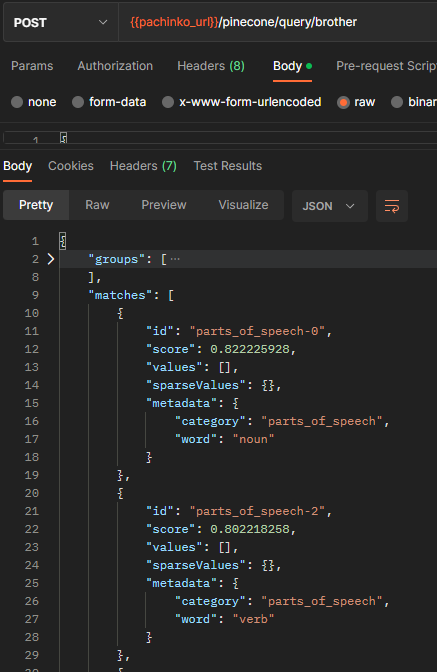
This screenshot might look scary – but what it is saying, is that the word brother is most closely associated to the “noun” embedding than it is to the “verb” embedding.
We can extend this to actually compare the word “brother” to examples of parts of speech and see which grouping it sits most closely to:
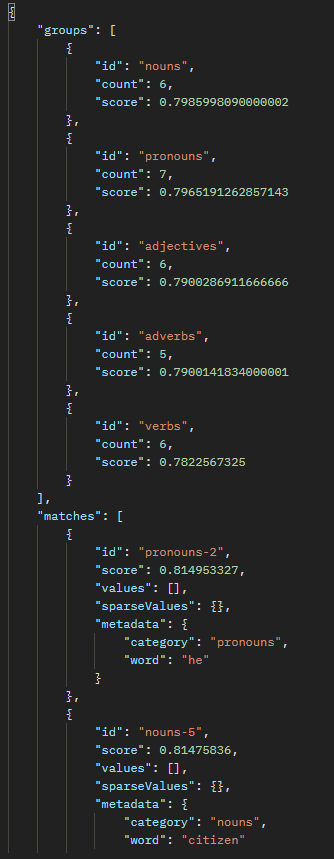
We can see that brother is most closely related to nouns, then pronouns – with the strongest relationship being to the word “he”.
Next, let’s try and sort it by gender:
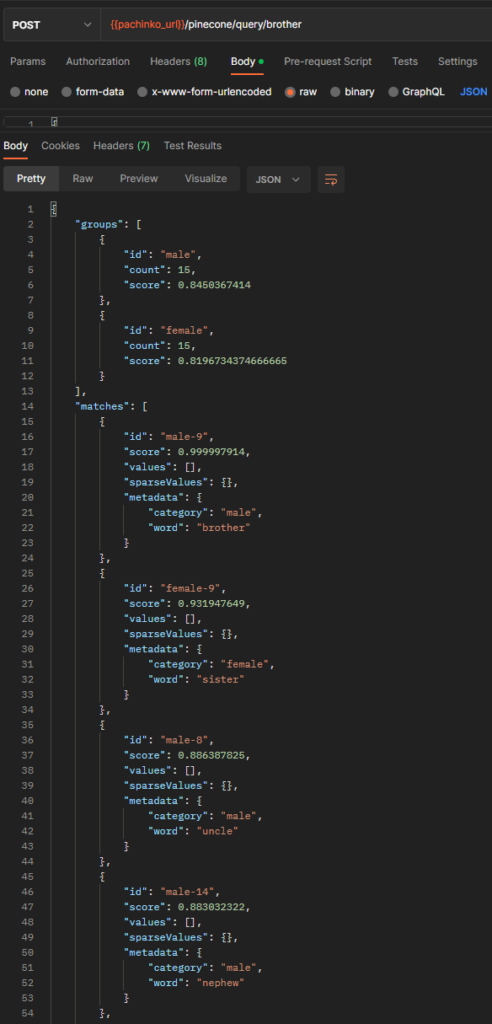
We can see that it is more closely associated to “male” than “female” in groups (this is the average of all the male matches that were returned).
However, if we look at the matches, we see something interesting. The closest (and almost perfect match) is the word “brother” which makes sense – because that was the word we gave it. However, the second closest match was sister. It makes sense that opposites would have a close relationship to each other, but also it’s easy to intuit why brother is more closely related to sister than it is to uncle or nephew.
Uncovering Biases
We can do some simple comparisons to gauge relationships between words and to see if we can uncover potential biases. It’s important to note that the relationships and their meaning in “embedding space” are opaque. We are looking at a very narrow slice of an exceptionally large space, and drawing conclusions.
Each heading here corresponds to the word that was sent and in brackets, we have the “namespace” or group of words that we are querying.
The Doctor (gender) – Male
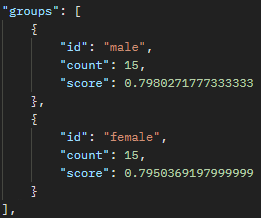
The Nurse (gender) – Female
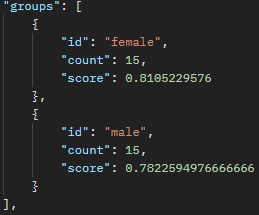
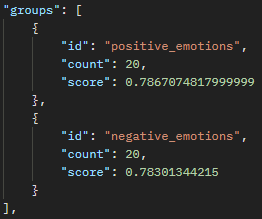
Child (emotion) – Positive Emotions
Teenager (emotion) – Negative Emotions
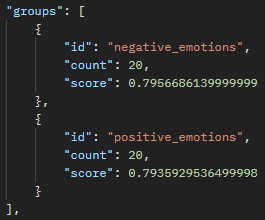
Each of these groups show here, then correspond to different words that have been fed into the vector database (for example teenagers are most closely associated to the emotion “depressed”).
Also, we can look at score to see how wide the discrepancy is between the associations. For example, “The Doctor” has a different of 0.004 between male and female, while “The Nurse” has a different of 0.03 between female and male. This appears to say to me that nurses are more strongly correlated to women than men, while doctors are generally more “male” but the line is less distinct.
With a Grain of Salt
This is a very rudimentary exploration of the relationships between words and phrases in these highly complex spaces. There are far better authorities for assessing bias and the ethics of these models than myself, and I believe it is imperative that any users of AI are aware of the ethical issues that these systems raise. A good start to explore these issues is the FastAI course on ethics in AI.
While these systems are impressive, they are also systems with real properties and relationships. By learning how they are constructed and how they are able to derive meaning as well as create it, we can better gauge how to implement them responsibly – while also demystifying their inner workings.